

对于一个SEO新手来说,你不需要考虑太多的东西,明白了伪原创也是制胜的法宝的真谛,了解获取外链资源的方法,足以让你受益匪浅。而随着SEO工作的不断深入,你也就会慢慢的发现充分利用好网络给予你的一针一线的重要性。了解搜索引擎的工作原理,其意义自然不在话下。
搜索引擎的工作原理,在我们的培训中也经常会被提及,简单来说,主要是三个步骤,爬行和抓取,预处理(因为索引是预处理中主要组成部分,故也有人将这一步称为索引),排名。排名这一块设计算法问题,暂且不去深究,这里主要说说爬行和抓取以及预处理两个方面。
一、爬行和抓取
通过蜘蛛程序,各搜索引擎在访问网站时都会先去查看网站根目录下的robots.txt文件,从而获取网站中被禁止爬取网址的信息。对于被禁止抓取部分的网址,不会被搜索引擎收录,但是需要注意的一个现象是,百度目前会对部分将百度蜘蛛屏幕的网站以下列类似淘宝网的形式显示,据个人不完全观察发现,这种现象正逐渐变的普遍起来(特别强调一点,这不是说百度不遵守robots协议了,打开此类收录网址的快照,你会发现快照为空)。
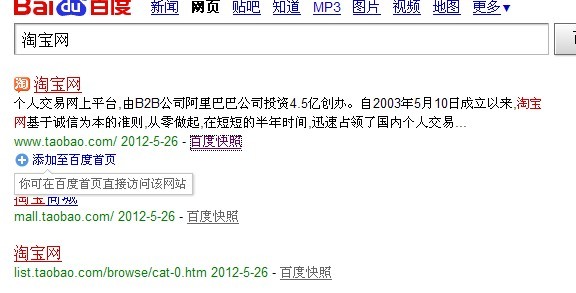
为了获取更多的信息,蜘蛛会通过跟踪页面上的链接来抓取页面。从理论上来说,蜘蛛可以通过链接抓取整个互联网上的信息,但是在实际操作中,考虑到页面的复杂程度,蜘蛛会采取深度抓取和广度抓取两种方式来进行页面抓取的工作。为了避免重复爬行和抓取,搜索引擎会建立包括已发现但未被抓取以及已被抓取的两个网页地址库进行参考对比,而被抓取的页面会进入原始的页面数据库。到此为止,原始数据库的建立就告一段落了。
二、预处理(索引)阶段
原始数据库建立完毕,搜索引擎会对网页进行文字提取的处理,当然,除了页面上显示的文字外,搜索引擎还会对诸如meta标签、flash替代文件,锚文本、alt标签等部分的文字进行提取。提取文字完毕,便会进入下一个阶段:分词。
不管百度算法多么垃圾,但是不可否认的是,百度的中文分词技术在搜索引擎中的霸主地位无人可以撼动。对于页面上抓取到的文字,搜素引擎会进行分词处理,比如将“瘦小腿方法”分为“瘦小腿”、“方法”两个部分。而分词的方法,一般会有词典与统计两种手段。词典嘛,不需要太多解释;至于统计,是指通过分析大量文本从而计算字与字之间相邻出现的概率,概率越大,越容易形成一个词。百度目前是将两种方法结合使用,来达到最佳的效果。
或许说到这里,大家会问,针对一些中文中常出现的词,比如“的”、“了”、“呀”之类没有实际意义但是使用频率又很高的词,会怎么样处理呢?答案是剔除,从而提高搜索引擎的计算效率。
在浏览网页的信息时,我们会发现,有一些板块,在网站是重复出现的,比如“导航”、“广告”等,这部分东西,对于所属页面的显示内容来说,并没有实际的意义。自然的,搜索引擎也会将此部分内容进行处理,从而筛选出所收录页面阐述表达内容的最终文字部分。当然,文字部分筛选出来之后,搜索引擎还会对各个网页上所显示的最终文字内容进行对比,从而删除掉重复的内容进行显示。
好了,经过上述的几个步骤,就可以建立索引库了,此时的索引会分为正向索引和倒排索引两个阶段。正向索引,可以简单的理解为将收录页面的网址为主键,以该页面上进行分词处理之后的结果为内容建立起的数据库,如下图所示。

正向索引结束,我们可以发现还不能用于排名,这时就需要倒排索引,即以关键词为主键,以包含该关键词的网址及对应内容为内容建立索引数据库,如下图所示。

至此,搜索引擎再通过对链接分析以及特殊文件的处理,预处理(索引)阶段也就落下帷幕了。从中我们也可以看出,深入了解了搜索引擎原理,对于日常的SEO工作理解以及启发作用还是十分明显的。比如,你在伪原创的过程中,只是草草的给一些文章加一些简单的助词或者对小部分的文字内容进行简单的修改,不好意思,你的文章在预处理甚至是爬行和抓取阶段就被pass了。
(本文"搜索引擎工作基本原理是怎样的"的责任编辑:SEO学堂) 鲁公网安备37131102371371号
鲁公网安备37131102371371号